基于参数化的接口自动化测试
背景
接口测试,简单来说是按照一定的参数请求接口,然后对返回值做校验。平时工作中,如果是针对单个接口进行测试,我们可以使用 Postman 等工具。当我们需要对大量接口进行测试,手动使用工具会花费大量的时间,因此需要通过一些自动化的方式来实现测试。
接口自动化是每个质量团队都会涉足的领域,每个团队都有自己的理解和实践方法。究其原因,是因为接口自动化是一个投入低产出大的工作。
接口自动化的实现方式很多,既可以使用工具,也可以编写代码来实现。就编写代码而言,又有两种不同的思路:一种是针对每一个接口编写一个测试用例,再通过测试框架将这些用例组装起来;另一种是只编写一个测试用例,其方法主要包括组装请求参数、请求接口和校验返回结果,再通过参数化的方式传入测试数据,从而实现接口自动化测试。
两种方法各有优劣。前者由于每个接口编写一个测试用例,代码量会比较大,也容易出现冗余,且后续新增用例时也得重新编写用例代码,较为耗时。但这种方法的好处是,所有的逻辑都写在测试用例代码中,容易理解。后者的优势是代码简洁,没有冗余代码,编写用例基本不用再编写代码,可以大大提升新增用例的效率。但也存在一些劣势,比如对参数化的用例编写格式要求较高。
鉴于第一种方法的使用较为普遍,相关介绍也比较多,本文着重探讨第二种方法即参数化接口自动化测试的设计与实现。
设计思路
总体思路
参数化的核心,是将测试用例与测试代码分离。对于接口自动化测试,需要将接口的请求参数、校验信息等,与实现接口测试的代码分离。代码部分主要包括以下功能:
- 加载测试数据
- 组装测试用例参数
- 参数化执行测试用例
- 接口返回值校验
测试数据
编写一个接口的测试用例,需要的数据无外乎两部分:请求信息和校验信息。请求信息主要包括 URL、请求方法、请求参数、Headers 等,其中 URL 的域名部分和 Headers 通常都是固定的。为了减少测试数据的冗余,可以考虑将其摘出,放到配置中。
因此,对于测试数据,可以分为两部分:配置和用例。其中配置部分主要是一些共用的数据,而用例部分则是具有差异性的数据。
在测试数据的文件选择上,常用的选择有 Excel、JSON/YAML 等。Excel 的好处是直观,但问题是难以查看修改记录;JSON/YAML 虽然直观性不如 Excel,但结构清晰,且可以通过 Git 提交记录查看修改记录。最终选择 YAML 存储测试数据,之所以选择 YAML 而不是 JSON,原因是 YAML 更易于读写。
用例设计
接口自动化测试,除了单接口测试,还有全流程测试。在全流程接口自动化中,经常需要动态获取参数、做一些特殊处理。为了实现这些功能,这里引入以下两个特性:
- 参数占位符
- 前后置脚本
参数占位符
在编写测试数据时,对于需要从前序用例返回结果中获取参数的参数字段,可以用参数占位符替代。格式有如下两种:
$name#expr$$name#expr#cls$
name 是前序用例的名称,expr 是欲从对应用例返回结果中取值的字段的 JSONPath 表达式,cls 是指定该字段的类型,如果不填写则根据返回值本身的类型自动判断。
比如,前序用例名为 generateId,功能是生成一个 ID 用于后续操作,返回值中 data.id 为生成的 ID。后序用例功能是根据该 ID 获取信息,则参数可以写为:params: {"id": "$generateID#data.id"}。
前后置脚本
对于一些业务,全流程接口测试中,需要做一些特殊处理,或是请求参数比较特殊,无法从前序用例返回值中获取,这里就需要针对这个用例单独处理。为了实现单独处理的逻辑,这里引入前后置脚本。
前后置脚本主要可以做以下两件事:其一,在脚本中处理一些特殊操作,如删除、修改数据库中的某些数据或调用其他接口从而构造特定场景;其二,通过一定方法获取后序用例需要的特殊参数,并存到本条用例的返回结果中,配合参数占位符,实现特殊参数的动态获取。
返回值校验
接口返回值的校验是判断一个接口是否通过测试的关键。考虑到本业务绝大多数接口的返回值均为 JSON 格式,以下所有情况均只考虑 JSON 格式返回值的校验。
对于一个接口的返回值,存在一些确定的字段,也存在一些不确定的字段。对于确定的字段,可以做精确判断。但对于不确定的字段,只能做模糊判断。如生成 ID 的接口,无法提前知道新生成的 ID 具体为何值,这种情况可以校验返回值中是否存在该字段。
为了满足不同情况的校验,这里定义了如下 4 种校验规则:
eq: [expr, value]len_eq: [expr, value]has: [expr]regex: [expr, regex]
第一种是最常用的精确校验,即校验返回值中 JSONPath 表达式为 epxr 的字段的值与 value 是否相等。
第二种是针对返回值中含有 List 的情况,校验返回值中 JSONPath 表达式为 expr 的 List 字段的长度与 value 是否相等。
第三种是判断返回值中 JSONPath 表达式为 epxr 的字段是否存在。
第四种是针对返回字段中部分确定、部分不确定的情况,校验返回值中 JSONPath 表达式为 epxr 的字段的值是否匹配正则表达式 regex。
通过组合以上四种校验规则,实现对接口返回值的校验。
技术实现
流程及结构
本文的接口自动化测试基于 Python 3.6,测试框架使用 Python 下最常用的 pytest,接口请求使用 requests,参数化测试使用 parameterized。
整个自动化测试的流程如下图所示:
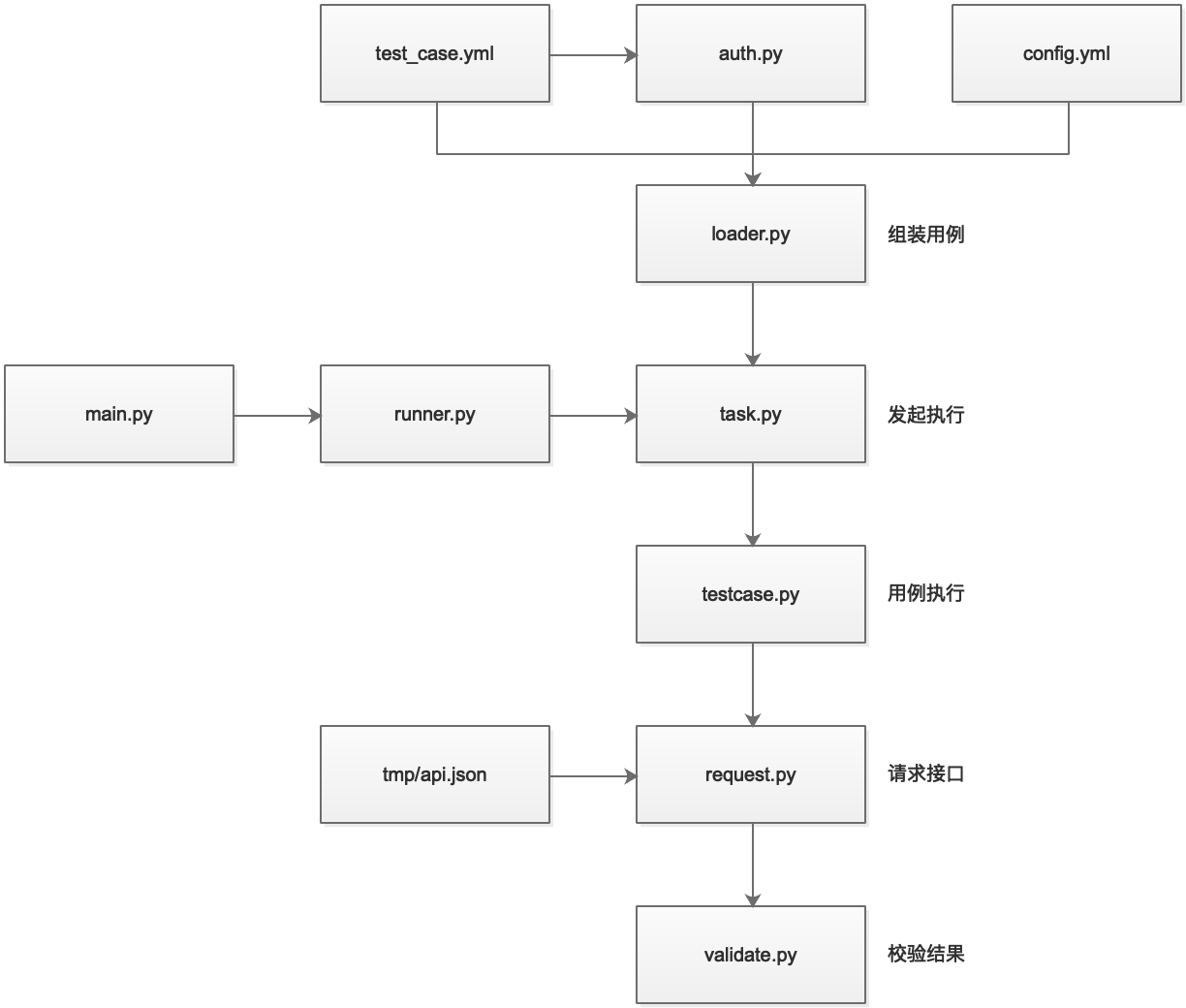
结构目录如下:
1 | . |
case 目录用于存储测试数据,conf 目录用于存储配置文件,utils 目录用于存储实现方法。
main.py 为项目启动文件,启动后调用 runner.py 执行 pytest 测试,测试方法指定为 task.py 中的测试类。
task.py 的测试类(继承 testcase.py 中的测试基类)中,测试用例使用 parameterized 进行参数化构建,参数由 loader.py 读取测试数据文件和配置文件后组装而成,其中 auth.py 用于账号认证。
对于每一条测试用例,request.py 用于从临时目录 tmp 中获取前序用例接口的返回值并替换参数占位符生成最终的请求参数,并发起请求、获取结果。validate.py 用于对返回结果进行校验。
参数化执行用例
parameterized 是 Python 的第三方模块,可以在常用测试框架(unittest、pytest、nose)下进行参数化测试。
以下是最简单的一个例子:
1 | from nose.tools import assert_equal |
对于需要参数化的方法,在方法前标注 @parameterized()(unittest 需标注 @parameterized.expand()),括号内传入参数列表,即可将该测试方法封装为参数化方法。
在测试执行时,parameterized 会自动拼接新的测试方法名,规则是 方法名_序号_传入的第一个参数。
上面的例子是直接将参数写在标注中的。在实际使用中,通常是通过别的方法获取参数化的列表。以 task.py 为例:
1 | # task.py |
Loader 类所做的事情,是读取测试数据文件,结合配置文件的信息,将每一个用例解析成一个字典,格式为:
1 | { |
解析占位符
由于占位符存在于 URL、请求参数之中,因此解析占位符时需要对各种不同类型做判断。主要思路是,通过正则表达式找出占位符($name#expr$ 或 $name#expr#cls$),获取 name、expr 和 cls 的值,然后从对应用例的返回结果中获取值并转换成相应的类型。
四、应用与总结
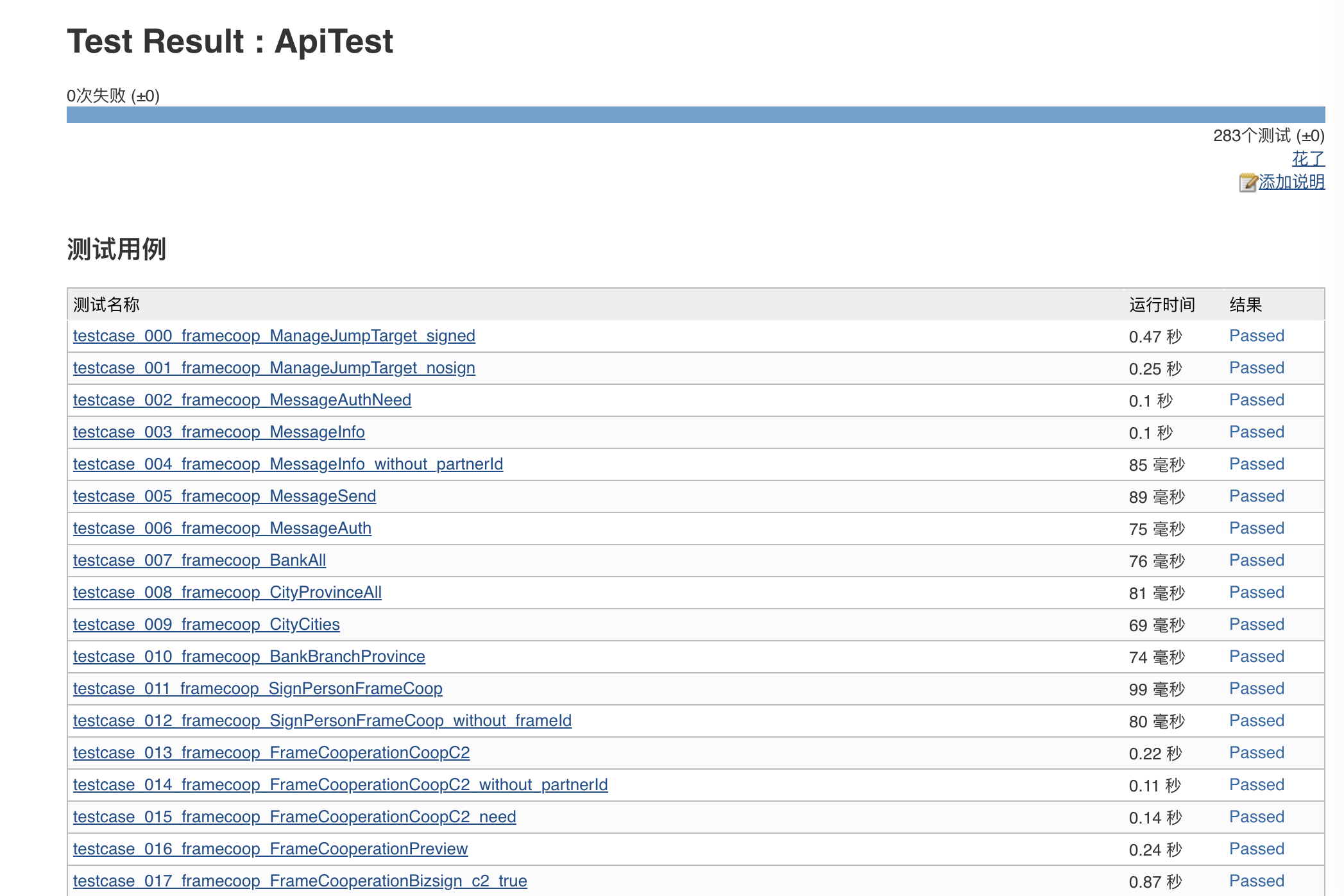
由于 pytest 可以生成标准 JUnit 报告,因此可以很方便地接入 Jenkins 并看到测试结果。
本接口自动化测试应用了参数化的思想,将测试数据与代码完全分离,通过 YAML 文件管理测试数据,既可实现单接口用例,也可以通过顺序关系实现全流程接口用例,大大降低了接口自动化测试用例的编写难度。